Segmenting Glomeruli and other structures from synchrotron X-ray microtomography datasets
InfraVis User
Anja Schmidt-Christensen
InfraVis Application Expert
Alexandros Sopasakis
InfraVis Node Coordinator
Emanuel Larsson
Other Contributors
Tools & Skills
Mask RCNN, Blender, Python
Other Keywords
Rat kidney data, Glomeruli, Tubuli, Tuft, Bowman’s space, Synchrotron, X-ray, microtomography
About
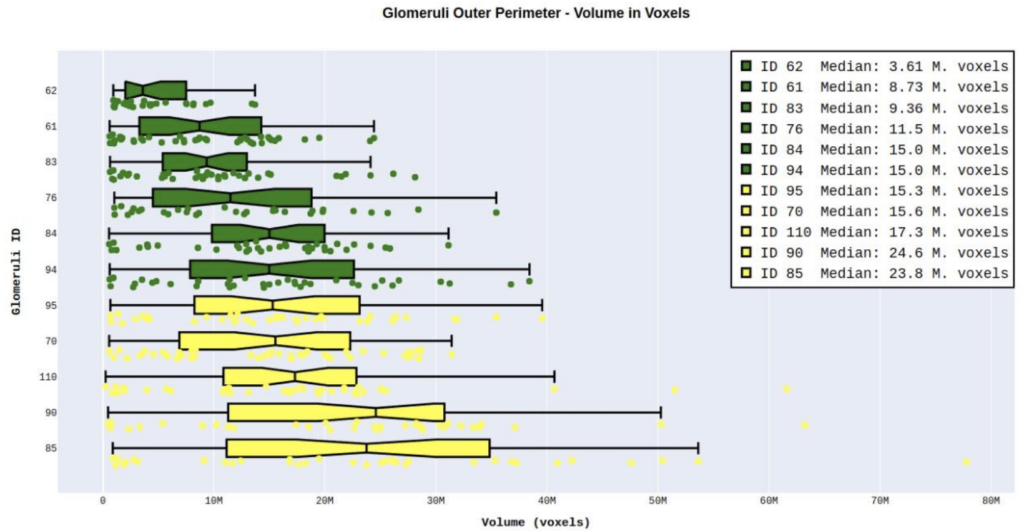
A machine learning based segmentation and quantification study to estimate the size of Bowman’s space. Bowman’s space is the difference between outer perimeter and Tuft in a glomeruli. Such approximations can reveal tendencies toward having or developing cancer.
Challenges & Opportunities
Diabetes is a long-lasting health condition with serious complications. We studied a new group of rats with a specific genetic mutation linked to diabetes. Regardless of their gender and blood sugar levels, these rats were overweight and had larger livers, hearts, and kidneys compared to normal rats. A study of the size of Bowmans space (difference between outer perimeter and Tuft of their glomeruli) can reveal tendencies toward having or developing cancer. In that respect advanced machine learning approaches are used to automatically segment and evaluate 3D volumetric information of many of the structures found within the tomography scans collected.
Accuracy is of paramount importance when trying to compute the difference in segmentations of Outer Glomeruli Perimeter and inner Glomeruli Tuft. A combinations of the mask RCNN machine learning model tougher with specially designed quantification python algorithms performing interpolations between segmentations was able to resolve these challenges and produce answers to the research problem questions.
Result & Potential
This project resulted in one publication submitted thus far and further research into human kidney data which is believed that it should produce similarly good results.
Project & Process
Mask R-CNN (Region-based Convolutional Neural Network) is a computer vision model designed for object detection, instance segmentation, and pixel-wise object masking in images. It extends the Faster R-CNN architecture by incorporating an additional branch for predicting object masks at the pixel level. Mask R-CNN operates in two main stages: (1) It identifies object bounding boxes using a Region Proposal Network (RPN), and (2) it segments the objects within those boxes into fine-grained masks. The architecture consists of a backbone feature extractor (e.g., ResNet), a Region Proposal Network, and parallel branches for bounding box regression, class prediction, and mask segmentation. This model excels in tasks like object recognition and precise object delineation, making it a valuable tool in computer vision applications like image segmentation and instance-level object detection.